Problém vážené splnitelnosti booleovské formule
Problém
Je dána booleovská formule F proměnnných X=(x1, x2, ... , xn) v konjunktivní normální formě (tj. součin součtů). Dále jsou dány celočíselné kladné váhy W=(w1, w2, ... , wn). Najděte ohodnocení Y=(y1, y2, ... , yn) proměnných x1, x2, ... , xn tak, aby F(Y)=1 a součet vah proměnných, které jsou ohodnoceny jedničkou, byl maximální.
Je přípustné se omezit na formule, v nichž má každá formule právě 3 literály (problém 3 SAT). Takto omezený problém je stejně těžký, ale možná se lépe programuje a lépe se posuzuje obtížnost instance (viz Selmanova prezentace v odkazech).
Zadání
Řešení problému vážené splnitelnosti booleovské formule některou z následujících metod:
- simulované ochlazování
- genetický algoritmus
- tabu prohledávání
Použité algoritmy
V rámci této úlohy jsem imlepmentoval tři pokročilé iterativní metody (genetický algoritmus, mravenčí algoritmus a stimulované chlazení.)
Všechny tyto metody nejsou deterministické, tzn. že nemusí dát oprtimální řešení.
U všech metod je použité stejné ohodnocení. Jedná se o součet vah u ktercýh je 1 a dále ohodnocení toho, zda je konfigurace taková, že je formule splnitelná. Toto ohodnocení je suma vah+1, tedy tolik, aby konfigurace, kde všechny proměnné mají ohodnocení 0 a formule je splnitelná bylo vyšší, než konfigurace, kde všechny proměnné jsou 1, ale fomule je nesplnitelná.
Genetický algoritmus
Getický algoritmus je založen na chromozonu, který má délku počtu proměnných (booleany).
V první fázi GA vygeneruje první generaci, tedy vytvoří náhodných 20 chromozonů a začne 2. fáze.
V té dochází ke křížení (každý jedinec se skříží jiným, tedy vybere si jiného ke křížení, tudíž každý jedinec může být křížen 1 až n-1). Dále dochází i k mutaci k té může dojít maximálně 2x pro každého jedince, dochází při ní ke změně jedné proměnné v rámci chromozonu.
Tato druhá fáze je zakončena tím, že do nové generaci je přeneseno 10 nejlepších z minulé generace a je zachováno pouze 64 nejlepších z těchto jedinců.
2. fáze se opakuje tak dlouho dokud během 15 po sobě následujících generací nevznikl lepší jedinec než dříve...
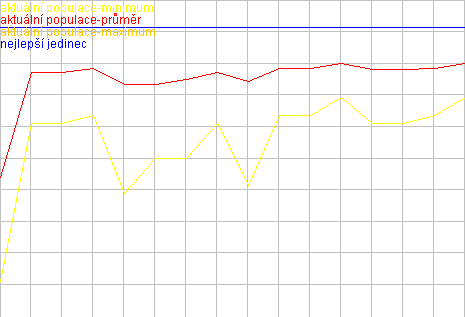
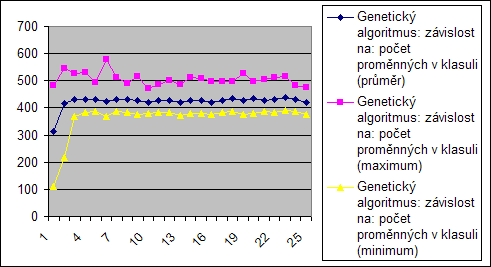
Na tomto grafu je vidět ukázka z výpočtu jedné z instancí. Je z něj patrné jak rozmanitá je populace z hlediska ohodnocení v průběhu celého výpočtu a jak se lehce zvyšuje průměr.
Mravenčí kolonie
Mraveční kolonie pracuje na principu volby proměnné mravnecem dle feronomu. To je realizováno polem, které obsahuje intenzitu feronumu na jednotlivé proměnné.
Na začátku je feromon na všech proměnných stejný (1., tzn. nenulový ).
V každém kroku vznikne 4xpočet proměnných (kvůli složitějším instancím) mravencům. Každý z nich vybere proměnou s určitou pravděpodobností. Feronomy v každé kroku částečně mizí a doplňuje se novými, ty jsou intenzivní dle toho v jak dobré konfiguraci se nacházela.
Toto celé opět běží po několik kroků, při kterých nebylo nalezeno lepší řešení, zde je to 20 kroků.
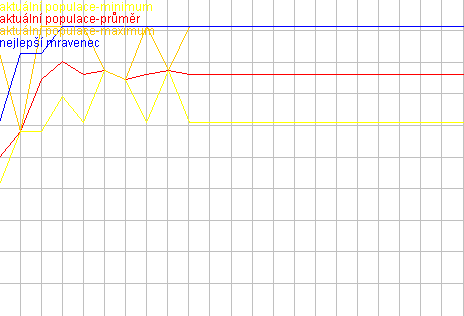
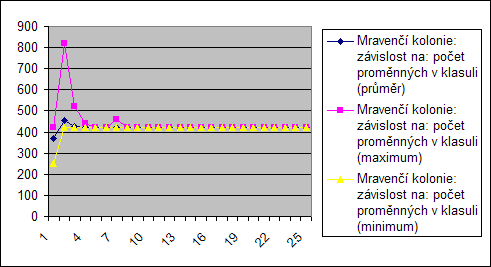
Na tomto grafu je vidět ukázka z výpočtu jedné z instancí. Je z něj patrné jak jsou zde generováné rozmanité konfigurace z hlediska ohodnocení v průběhu celého výpočtu. Dále je zde vidět, že nejlepší konfigurace nemusí být vždy generovány. Pokud např. mravenci náhodně zvolí obdobně špatné konfigurace, budou i přesto, že zdaleka nejsou nejlepší mít více feromonů a bude tedy i později zkoušeny obdobné konfigurace. To se dá eleiminovat pouze větším počtem mravencům, kde oravděpodobnost tohoto jevu klesá.
Simulované chlazení
Tato metoda pracuje na princupu náhodného zkoušení konfigurací řízené proměnou - teplotou.
Tato teplota postupně klesá, čím nižší je, tím je více nejde přijímat horší řešení než je stávající, tzn. že to nové řešení může být v nejhorším případě horší o hodnotu v závislosti na teplotě.
Teplota klesá v konstantím počtu kroků - 1024. Aby bylo eliminován fakt, že jsou různě složité instance, je v každém kroku generováno až 2xpočet proměnných proměnných konfigurací.
Tím postupně získávám stále užší interval možncýh ohodnocení, až interval nelze zmenšit a algoritmus končí.
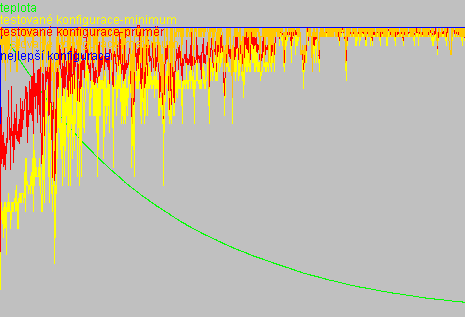
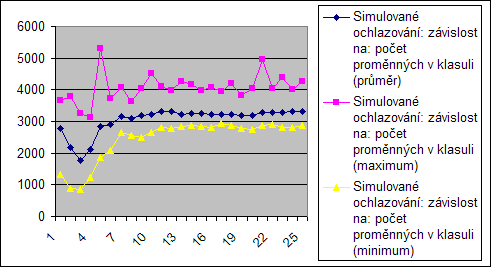
Na tomto grafu je vidět ukázka z výpočtu jedné z instancí. Je z něj patrné jak postupně klesá teplota i v jakých rozmezích se pohybuje aktuální hodnota opt. kritéria, i kde bylo nalezené dané nejlepší řešení.
Měření
Závislosti
Aplikace nabízí měřit závislost času nebo počtu operací. Z důvodů odstanění rušívých vlivů jsem uvedl pouze závislost počtu operací.
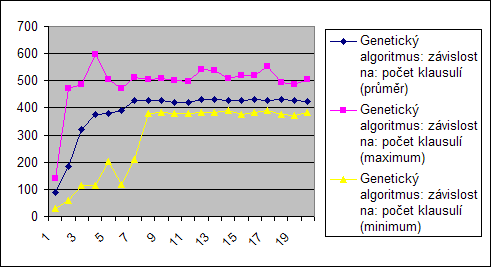
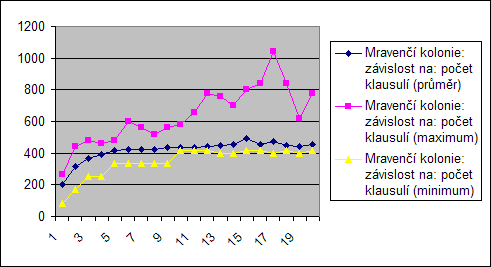
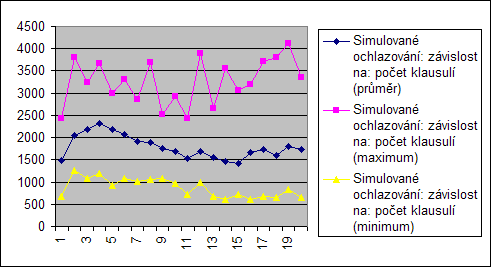
Počet klasulí
Algoritmů přímo závisí na počtu proměnných (počet mravenců, počet změn v při stejné teplotě), resp. počet různých konfigurací.
Proto počet klasulí při konstatních ostatních hodnotách nemá přímí vliv.
Přesto je vidět že grafy nejsou konstantní. Zvyšování počtu operací v začátku grafu znamená, že nemusí být použity všechny proměné (1 klasule, 3 proměné na klasuli, 6 proměnných...) V další části by tedy měl být graf konstantní. Není tomu tak ale u všech, je to způsobeno tím, že s počtem klasulí ubývá počet splnitelných klasulí a tak poté je mnohem těžší najít změny, které se liší jen málo (simulované ochlazování) nebo se pravděpodobnost že lepší řešení se bude hledat déle roste (mravenci).
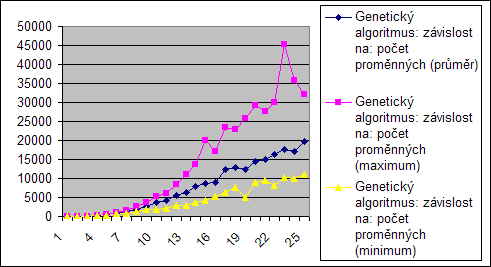
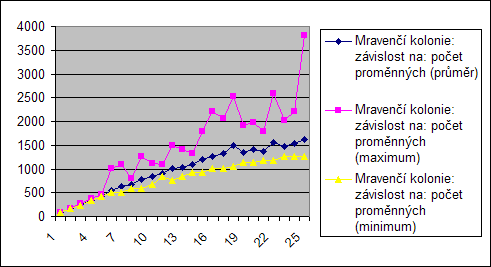
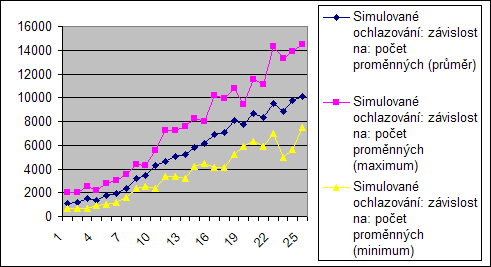
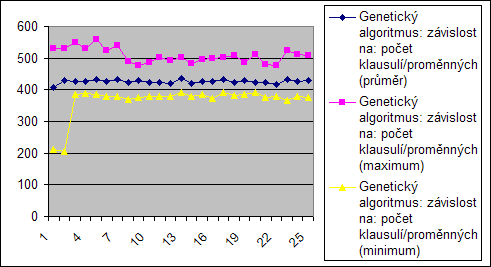
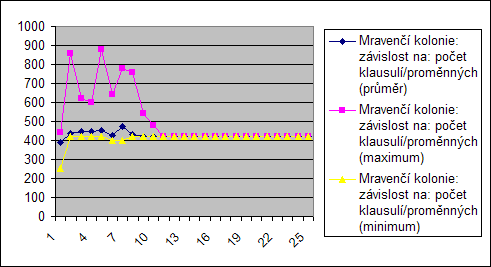
Počet proměnných
Jak již bylo řečeno při předchozím měření, algoritmy jsou závislé na počtu proměnných. To je z těchto grafů zřetelné, protože s počtem proměných pročte i počet operací, resp. testovaných konfigurací...
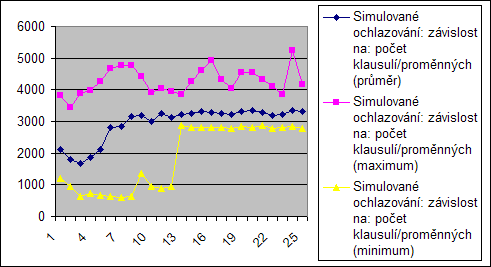
Počet klasulí / počet proměnných
Toto měření bylo založeno na proměném podílu poču klausulí a počtu proměnných.
Generátor pracuje tím způsobem, že má konstantní počet proměnných a dopočítává počet klasulí, proto ani zde není přímí vliv a grafy od jistého bodu vypadají konstantně. Jedná se opět o bod kde je vysoká pravděpodobnost, že budou využity všechny proměnné...
Počet proměnných v klasuli
V těchto grafech je opět konstatní počet proměnných, mění se jen délka konsulí. Proto ani zde není vidět přímý vliv na tuto proměnnou.
¨
Nekonstantní je graf opět v začátku. Tam se opět projevu obdobný vliv jako v předchozích měřeních.
Porovnání algoritmů
|
Genetický algoritmus |
Mravenčí kolonie |
Simulované ochlazování |
| Genetický algoritmus |
| Horší výsledek |
|
0.02 % |
0.05 % |
| Horší nebo stejný výsledek |
|
99.81 % |
100.00 % |
| Stejný výsledek |
|
99.79 % |
99.95 % |
| Lepší nebo stejný výsledek |
|
99.98 % |
99.95 % |
| Lepší výsledek |
|
0.19 % |
0.00 % |
| Mravenčí kolonie |
| Horší výsledek |
0.19 % |
|
0.22 % |
| Horší nebo stejný výsledek |
99.98 % |
|
100.00 % |
| Stejný výsledek |
99.79 % |
|
99.78 % |
| Lepší nebo stejný výsledek |
99.81 % |
|
99.78 % |
| Lepší výsledek |
0.02 % |
|
0.00 % |
| Simulované ochlazování |
| Horší výsledek |
0.00 % |
0.00 % |
|
| Horší nebo stejný výsledek |
99.95 % |
99.78 % |
|
| Stejný výsledek |
99.95 % |
99.78 % |
|
| Lepší nebo stejný výsledek |
100.00 % |
100.00 % |
|
| Lepší výsledek |
0.05 % |
0.22 % |
|
Z výše uvedené tabulky je patrné že na mnou náhodně generované instance (pro 10 000 instancí) byli výsledky podobné. Ve více jak 99% instancí dávali, všechny algoritmy shodné výsledky (to tedy neznamená, že se jednalo o optimální ale o shodně ohodnocené).
S ohledem na hodnoty blízké 100%, nelze jednoznačně říci, který s algoritmů pracuje nejlépe (není rozdíl nijak významný). Z tabulky zde jen jednozančně říci, ža na testovaných datech nejlépe pracoval algoritmus simulované ochlazování, protože nedal nikdy horší výsledek než ostatní.
Data
Data byla změřena aplikací a zpracována v MS Excel.
Program
Aplikace je psaná v Javě 1.5 (JBuilder 2006). Pro spuštění bude možná nutné upravit cestu k interpretu v souboru run.bat.
Závěr
V této úloze jsem implementoval 3 různé prokročilé iterativní metody.
Tyto metody jsou polynomiálně složité v závislosti na počtu proměnných. Algoritmy však obecně nezaručijí nalezení optimálního řešení.
Algorimty mají předem spočitatelnou maximální dobu výpočtu (čas / počet operací) - např. simulované ochlazování: f(počet proměnncýh, ekvilibrium).
V rámci porovnání mezi metodami bylo zjištěno, že algoritmy jsou si prakticky rovnocené, ačkoliv při určitých instancí mohou klást jiné výsledky. Tyto rozdíly jsou ovšem mizivé a s ohledem, že jsou závislé na náhodně generovaných hodnotách nelze s jistoutou tvrdit závěry obecně.